Parallel point cloud registration
Hanzhou Lu, Yujie Wei CMU 15-618 2016 Fall
This project is maintained by HanzhouLu
SUMMARY
In this project, we plan to parallelize the Iterative Closest Point (ICP) registration algorithm for point cloud processing system using the NVIDIA CUDA library.
ALGORITHM
Point Cloud Registration (PCR) plays an important role in computer vision since a well-aligned point cloud model is the bedrock for many subsequent applications such as Simultaneous Localization and Mapping (SLAM) in the robotics and autonomous cars domain or Automatic Building Information Modeling in the architectural industry. Nowadays, point clouds are usually gathered by multiple cameras or laser scanners with their own coordinate systems. The objective of Point Cloud Registration (PCR) is to search a transformation that could align a reading point cloud with a reference point cloud in a consistent coordinate system. The process of finding the transformation and the closest point involves lots of matrix operations that are usually independent of each other. Given the intermediate level of dependency and the huge size of the problem, exploiting the parallelism can be a good alternative to speed up the algorithm.
The objective of the algorithm can be formally expressed as follows:
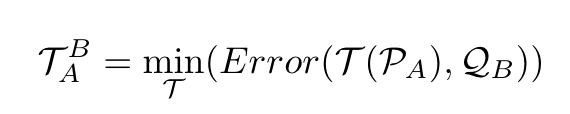
where T is the transformation, P is the reading point cloud captured in the coordinate System A, and Q is the reference point cloud captured in the coordinate system B. The error is defined as the distance between each closest point pairs in different point clouds.
The generic algorithm (Besl, 1992) is shown below:
 The program will first apply filters to the point clouds to remove outliers, then start searching from the
initial transformation. In each iteration, the algorithm establishes the correspondence, creates point
pairs from the reading and reference, conducts transformation over the reading point cloud, and find
the transformation that minimizes the match error. The process will continue until the result converges
or reaches the maximum number of iteration.
The program will first apply filters to the point clouds to remove outliers, then start searching from the
initial transformation. In each iteration, the algorithm establishes the correspondence, creates point
pairs from the reading and reference, conducts transformation over the reading point cloud, and find
the transformation that minimizes the match error. The process will continue until the result converges
or reaches the maximum number of iteration.
A more recent implementation of ICP is shown below:
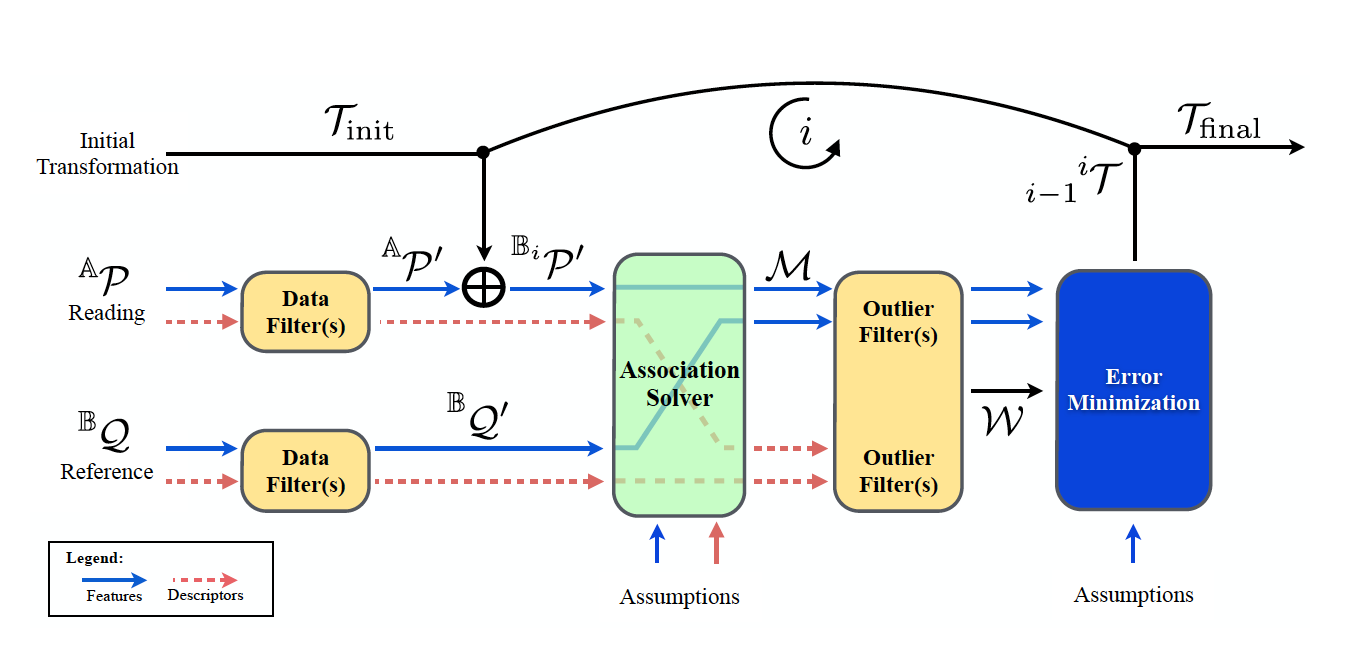
THE CHALLENGE
The challenges of the project come from the problem size and the dependency of the transformation series. A typical point cloud usually contains millions of points that may cause the cache performance to be quite poor. Also, notice that the next transformation has to be calculated based on the previous result that limits the level of parallelism. Nowadays, to make the algorithm more robust when dealing with occlusions and outliers, some refined versions of ICP adopt different distance metrics and objective functions that bring new challenges. Our goal is to develop a robust parallel implementation of ICP that could be extended in the future to handle unexpected changes.
Besides, to accelerate the key computation process, the data structure should provide support for fast search and inference. According to S. Rusinkiewicz and M. Levoy (2001), k-d tree is a good candidate for ICP. Therefore, the project will also involve parallelizing the algorithm using the k-d tree data structure.
RESOURCE
The Point Cloud Library (n.d.) provides a CPU implementation of ICP based on their self-developed point cloud format which can be a good sequential reference of our project. However, since our project may run on different point cloud format, we’ll implement our own sequential version and parallelize it in CPU and CUDA.
GOALS AND DELIVERABLES
SEQUENTIAL SOLUTION
In this phase, we are going to read papers and algorithm about an implementation of image registration. And we will get it work as a sequential version on CPU.
PARALLEL SOLUTION ON CPU
In this phase, we will do a high-level optimization on our sequential version including but not limited to parallelization over different blocks in a matrix, cache optimization, and independence exploitation.
PARALLEL SOLUTION ON NVIDIA GPU
In this phase, we will do specific optimization such as vectorized operations, shared memory, and other available resources in CUDA to make our code run faster on NVIDIA GPUs.
3D MODEL VISUALIZATION
We will provide a visualization of the aligned point cloud model to make the outcome understandable.
(OPTIONAL)COMBINE REGISTRATION WITH SEGMENTATION
After we accomplish goals above, we will try to do points segmentation which is partition points into different parts and label them. This part can also be speeded up by parallel programming.
PLATFORM CHOICE
We choose CUDA as our parallel library because shared memory space in NVIDIA GPUs can be used as a programmable cache. It allows us to cache specific data which is quite helpful while doing matrix calculation. For a specific problem like matrix multiplication, the support for programmable cache and vector intrinsic will allow us more space to perform delicate tuning and get better performance.
MIDWAY UPDATE
We have achieved most of the goals set in our proposal on time. First, we read several papers to figure out the algorithm and selected the equal-point optimization algorithm as our choice. The advantage of the equal-point algorithm is that it’s much more accurate than the equal-plane one. However, it also means much more computation which allows for a huge space for parallel improvement. Second, we have successfully implemented the sequential version of the point cloud registration program. Figure 1 shows how two point clouds with different coordinate systems (Left) can be perfectly aligned through automatic registration (Right). To establish a reasonable baseline for the project, we mimic the industry standard relying on Eigen, a highly-optimized matrix library that could provide a pretty good speed on modern CPUs. In a point cloud which contains 40,256 points, the serial program took about 80 iterations to converge with approximately 2.5 seconds per loop. Third, we profiled the program and realized that most of the time was spent on finding the matching pairs. Therefore, OpenMP library was introduced to parallelize the brute force point matching algorithm and achieve a 5.2x speedup on an Intel 4-core i7-4870HQ CPU. Since we successfully completed the goals set in the proposal, we believed that we should be able to produce the deliverables on the poster session.
Though the program works well in the test dataset, there are still many optimizations such as finding outliers, accelerating the match searching, extrapolation, and handling multiple scans that we can do to provide a better result in a shorter time. We will solve these problems in our next step. The final version of our code will be a parallel IPC program implemented on NVIDIA GPUs. Parallelized modules include match searching, coordinate normalization, motion decomposition and so on.
The goals of the final project are listed below:
- A parallel version of matching that supports fast search of point pairs.
- A parallel version pre-processing module to vexolize the point cloud so as to decrease the amount of computation.
- Implement the extrapolation and outlier removal module to increase the accuracy of the program.
- Visualized output.
The detailed plan can be found on the schedule part.
Work Completed
- Read paper about ICP and choose the Stanford 3D scanning repository as our dataset.
- Parse PLY file and process the large point cloud into small voxels.
- Find the matches of closest points in two different point clouds.
- • Normalize two coordinates and do the motion decomposition optimization.
- Implement the OpenMP parallel version of code on the CPU (Single node).
Schedule
| Task | Period | Person in charge |
|---|---|---|
| Parallelize Point Matching | 11/22/2016 - 11/26/2016 | Hanzhou Lu |
| Implement Outlier Finding | 11/22/2016 - 11/26/2016 | Yujie Wei |
| Parallelize Coordinate Normalization | 11/27/2016 - 12/01/2016 | Hanzhou Lu |
| Parallelize Singular Value Decomposition | 11/27/2016 - 12/01/2016 | Yujie Wei |
| Optimize #cores and #warps on NVIDIA GPUs | 12/02/2016 - 12/08/2016 | Hanzhou Lu and Yujie Wei |
| Optimize Cache Locality | 12/02/2016 - 12/08/2016 | Hanzhou Lu and Yujie Wei |
| Final Write-up and Poster | 12/09/2016 - 12/12/2016 | Hanzhou Lu and Yujie Wei |
Poster Session
At the poster session, we will showcase a parallel ICP demo demonstrating the processes of how two point clouds are combined together. An animation consisting of different steps during the point cloud registration will be shown on the poster session. To show the speedup of the parallel version of ICP, we’ll also test the program on different machines with different datasets, and analyze the pros and cons of using CUDA to parallelize the program.
Preliminary Result

REFERENCE
Besl, Paul J.; N.D. McKay (1992). "A Method for Registration of 3-D Shapes". IEEE Trans. on Pattern Analysis and Machine Intelligence. Los Alamitos, CA, USA: IEEE Computer Society. 14 (2): 239–256. doi:10.1109/34.121791
Pomerleau, François; Colas, Francis; Siegwart, Roland (2015). "A Review of Point Cloud Registration Algorithms for Mobile Robotics". Foundations and Trends in Robotics. 4 (1): 1–104. doi:10.1561/2300000035
S. Rusinkiewicz and M. Levoy (2001), "Efficient variants of the ICP algorithm," 3-D Digital Imaging and Modeling, 2001. Proceedings. Third International Conference on, Quebec City, Que., pp. 145-152. doi: 10.1109/IM.2001.924423
PCL - Point Cloud Library (PCL). (n.d.). Retrieved October 31, 2016, from http://www.pointclouds.org/
Final report: https://github.com/HanzhouLu/Parallel-Point-Cloud-Registration/blob/master/Final%20Report.pdf